It is said that mathematics is the language of science. Certainly if you want to be any kind of a classical scientist, you will probably need an extensive understanding of mathematics. Virtually every major field of science in academia today makes extensive use of mathematical formulas. Math is the chief gateway into just about any university science program; You usually do not start studying the subject of your choice (be it physics, chemistry, biology, astronomy, engineering, or whatever you decide upon) without first going through some math courses that are considered essential, and usually geared toward calculus. As such, it is important for post-secondary students to understand math, especially calculus.
This is a bit unfortunate, because in fact much of the math that is taught in university is not especially useful in the real world; Mathematics is a very broad field, and although most scientists and engineers do end up using math extensively on their jobs, it is usually math of a different variety than what they learned in university. Nonetheless, it is in the best interests of most any new university student to understand calculus-level math, and so this page attempts to be an introduction to the absolute most basic concepts of post-secondary math.
Please be advised that this page is not very well organized or put together. I am not a math whiz; As much as I like computers, I am lousy at math. There once was a time when the two seemed inseparable, back in the early days when the only people who used computers were scientists or mathematicians, but in this day where computer whizzes are a dime a dozen, you don't have to know math to know computers anymore. Like many of the other pages on my website, I made this page as much for my own reference as for anyone else's.
If you studied arithmetic in grade school, you probably studied the following order-of-operation rules for arithmetic calculations:
1. Do all calculations within brackets (()) first.
2. Do multiplication and division in the order they appear.
3. Do addition and subtraction in the order they appear.
In other words, multiplication and division come first, then you do addition and subtraction.
This resolves the issue of what to do with a problem like this:
10 + 20 / 2
(The slash represents division, as it does in most computer programming languages.) If you simply perform all the arithmetic operations in the order they appear, then you calculate: 10 plus 20 is 30, and 30 divided by 2 is 15, so the answer would appear to be 15. However, following the order-of-operations rules, you do the division first. Thus, calculate 20 divided by 2 first (which is 10), then add the result to 10. 10 plus 10 is 20, so the answer is actually 20.
Now take a look at this:
20 + 10 ------- 2 + 3
What is the answer? If you preserve the typical grade-school order of operations, then you divide 10 by 2 first (which is 5), so the expression becomes:
20 + 5 + 3
...Which is 28.
The correct way to do this problem, however, is to perform the numerator and the denominator of the fraction first. Do (20 + 10) first (which is 30), and then do (2 + 3), which is 5. Now you can divide 30 by 5, which gives you 6. The correct answer is 6.
When a horizontal bar is used for division, there are implicit brackets around the numerator and denominator. In other words, the numerator and the denominator should be calculated first, BEFORE they are divided.
A variable is a placeholder which has a definite, but unknown, value. For example, in the expression x + y = 10, x and y are both variables. They represent some kind of number value, but their exact values are not known. x could be 4 and y could be 6, x could be 7 and y could be 3, or they could both be 5. All of these are possible values of these variables.
Those who are used to computer programming will probably be comfortable with the concept of variables, but one irksome thing about math is that in math, variables cannot always be resolved to a definite number. In computer programming, every variable always has some value; Even if you don't set it to some value, the variable represents a definite number. Whether that number is set by the compiler or by the random shifting of bits in memory, there is a logical and definite reason why the variable has taken on whatever value is associated with it. In math, it is possible to have a variable which you cannot possibly resolve to a single number. The expression just mentioned is an example; There are several possible values for x and y, and without additional information, it is impossible to figure out exactly what each number is.
What is a "term" in mathematics? There are several ways of defining this word, but the simplest way (to me) is to consider a term to be the parts of an expression which are separated by addition (a plus sign) or subtraction (a minus sign). For example, in the expression a + b, a is one term, and b is another term, because they are separated by a plus sign. Thus, this expression has two terms. On the other hand, the expression ab (which is a times b) has only one term, because a and b are only separated by multiplication, not addition or subtraction.
Now that you know what a term is, you should also know...
What, then, are like terms? Like terms are terms which contain the same set of variables. This means that the exact same variables must be in each of the terms, no more and no less. For example, 3x and 7x are like terms. On the other hand, 3x and 7y are NOT like terms, because they have different variables. You can combine 3x and 7x; The expression 3x + 7x can be simplified as 10x. However, the expression 3x + 7y cannot be simplified this way.
An added nuance of like terms is that each term must be raised to the same power. For example, 3x cannot be combined with 7x raised to the power of 2. This is because 7x squared is really 7xx; Although it seems to have only one x in it, the exponent has the effect of putting two xs in the expression. So, like terms can be conclusively defined as terms which have the same variables, raised to the same power. Remember that if there is no exponent specified, this is equivalent to being raised to the power of 1. For example, x is exactly the same as x raised to the power of 1.
Also remember that anything multiplied by 1 is the same as not multiplying it at all. 1x is the same as x. Therefore, 3x + x equals 4x.
Don't get confused by the ordering of variables within a term. Remember that in multiplication, order makes no difference, so xy is exactly the same as yx. Thus, 2xy + 3yx can be simplified into 5xy. (Or, if you prefer, 5yx.)
A constant is a number with no variables. In the expression 3 + x + 4, 3 and 4 are constants. You can take the number 3 and do whatever you want with it, but in the end, 3 is still 3. Constants can be combined just as like terms, so this expression could be simplified as 7 + x.
A polynomial is an expression which contains two or more terms.
An expression which contains only one term is a monomial, which is not a polynomial. An expression which contains two terms is a binomial, and an expression with three terms is a trinomial. Binomials and trinomials are polynomials.
2x is a monomial.
2x + 3y is a binomial. (And a polynomial.)
2x + 3y - 8z is a trinomial. (And a polynomial.)
An "absolute value" is the magnitude of a value, regardless of its sign (i.e. disregarding whether the value is plus or minus). For example, the absolute value of +3 is 3, and the absolute value of -3 is also 3. Notice that the absolute value of anything cannot be negative. The absolute value is also sometimes expressed as the value's distance from zero.
Absolute value is notated by two vertical lines on either side of an expression. For example, | 2 | or | x | or | x+y | are all examples of absolute values.
A basic fact of working with absolute value equations is that if |x| = |y|, then x can equal either +y or -y, and likewise, y can equal either +x or -x.
A somewhat more complicated (but reasonably logical) fact about absolute values is twofold in nature:
If |x| > y, then either x < -y, or x > y.
If |x| < y, then x < y, and x > -y.
Let's take these two facts one at a time:
If |x| > y, then either x < -y, or x > y.
If the absolute value of x is greater than y, then either x is less than -y, or x is greater than +y.
For example, suppose that the absolute value of x is 7, and y is 5. x could be either -7 or +7, but either way, 7 has a magnitude higher than 5. -7 is less than -5, and +7 is greater than +5.
If |x| < y, then x < y, and x > -y.
If the absolute value of x is less than y, then +x must be less than +y, and -x must be greater than -y.
For example, suppose that the absolute value of x is 3, and y is 5. x could be either -3 or +3, but either way, 3 has a magnitude less than 5. +3 is less than +5, and -3 is greater than -5.
Algebra is the second most fundamental math skill (after arithmetic, which is mainly addition, subtraction, multiplication, and division). Almost every student learns algebra, and while some of them like it, many of them hate it.
What exactly is algebra? At its most basic level, algebra seems to be just the practice of representing numbers with letters. For example, you could say that x = 5. Then you can use the letter x in a formula. For example, you could say that x + 3 = 8. x is called a variable, which is simply a name which acts as a placeholder for some number value. If x is just going to be 5, this probably isn't too useful, but a very common and simple way that algebra makes things easier is when we talk about pi. The Greek letter pi is used to represent a number that starts off being 3.14, but keeps going (mathematicians theorize it has infinitely many digits). Whether you use a longer form of pi like 3.1415926535 or you just round it off to 3.14, it's easier when using this number in an equation to just write the Greek letter pi. This is one way that using variables can make life easier; you can still use the same number values, you just don't have to write so much down.
It all sounds simple enough so far, right? So what's so bad about algebra? Well, the problem is that algebra only begins with using letters to represent numbers; what algebra is really about is how to re-arrange numbers. Perhaps the most infuriating thing about algebra is that when you "solve" an algebra problem, very often the "answer" you come up with isn't really an answer at all. In arithmetic, you get used to seeing something like 8 + 5 x 12 and, using the order of operations, you can solve that problem and say "The answer is 68." Sometimes you can get this lucky with algebra, too. For example, if you see an equation that says x + 3 = 5, and you want to solve the problem by figuring out what x represents, you can pretty much tell just by thinking about this for a moment that x must equal 2, right? (After all, 2 is the only number that, when added to 3, equals 5.) Seems reasonable enough.
When you get into algebra, however, you'll have to get used to not having a nice answer. For example, consider the equation x + 3 = y + 5. Now, the best way to understand this equation would be to figure out what x represents, and what y represents. But guess what? You can't. The best you can say is that x = y + 2 and y = x - 2. You cannot ever come up with a simpler answer than this; at least, not without being given more information. If you later learned that x + 5 = 20, then you could solve for x and thereby figure out what y is, for example. But as it is, you're stuck. This happens a lot in algebra; in advanced algebra, you very rarely come up with an actual number for an answer, and instead of being told to "solve" a problem, you are simply asked to "simplify" an equation, which typically means to minimize how many different steps there are in it. That's just how math is; even if you don't know all the numbers you're working with, you can still work with them in a meaningful way as long as you're using the right formulas.
Algebraic manipulation is a re-statement or re-organization of an expression, usually used with equations, in order to solve the equation. Algebraic manipulations are a fundamental part of doing higher math, and the sad part is that they are not as well-understood as they ought to be. In my opinion, one of the most important things that a prospective math student can do to ease their studies is to understand the rules of algebraic manipulations well, for they are used constantly in university math.
A simple example of an algebraic manipulation is changing 2x = y into x = y/2.
Algebraic manipulations fall into three broad categories:
1. Commutative laws
2. Associative laws
3. Distributive law:
The distributive law goes like this:
a(b+c) = ab + ac
Simple examples of algebraic manipulation include:
Performing the same operation (addition, subtraction, multiplication, or division) on both sides of an equation.
Examples of using algebraic manipulation to solve equations:
Adding:
Suppose you have this equation:
x - 5 = 30
We can solve this by adding 5 to both sides of the equation...
(x - 5) + 5 = 30 + 5
Note that subtracting 5 and then adding 5 cancel each other out, so we can just eliminate those steps entirely and rewrite the equation as:
x = 30 + 5
Since 30 + 5 equals 35...
x = 35
Subtracting:
Let's start with this:
x + 10 = 70
Let's subtract 10 from both sides of the equation...
x = 70 - 10
70 - 10 is 60, so...
x = 60
Multiplying:
x / 2 = 20
We'll multiply both sides by 2 to cancel out the division.
x = 20 * 2
Therefore...
x = 40
Division:
x * 5 = 35
Divide both sides by 5 to cancel out the multiplication.
x = 35 / 5
So...
x = 7
These examples are very simple, but they do demonstrate basic equation-solving tactics through algebraic manipulations.
To factor an expression means to express it as the product of a multiplication operation. For example, 30 can be factored as 2 times 15, or as 3 times 10.
More complicated factoring often takes the form of factoring a trinomial like, say, 3(x^2) + 14x + 8. This trinomial can be factored to two binomials multiplied together: (3x + 2)(x + 4).
Fractions are often called rational expressions because they express a value as the ratio of two numbers. Although they are basically just a division operation rendered as a "number", there are a lot of little tricks about fractions to be known that makes working with them easier.
One of the most basic fraction concepts is the realization that if you multiply (or divide) both the top and the bottom of a fraction by the same value, the fraction's value remains unchanged. Expressed symbolically:
x xz - = -- y yz
If you have some fraction like x over y, and you multiply both x and y by the SAME value (here called z), the fraction's value stays the same. This is because the fraction is a ratio. If you have the fraction 2/3, you can multiply both numbers by 2 to get 4/6, or you can multiply both numbers by 5 to get 10/15. All of these numbers are proportional to each other; 2 has the same proportion to 3 as 10 has to 15. Thus, the ratio stays the same.
Perhaps the most important aspect of working with fractions is being able to implement a common denominator. The denominator is the bottom part of a fraction, and just as like terms (terms which have the same variables) can be combined easily, like fractions (fractions which have the same denominators) can be combined as well. There are several ways for getting a common denominator out of two fractions with different denominators. Here we'll look at a few.
One common way to combine unlike fractions is through cross-multiplying. What is cross-multiplying? It's a principle that goes like this: Suppose you have two fractions with unequal denominators, and you want to combine them so they produce one fraction. This is done by multiplying the numerator in each fraction with the denominator of the other fraction; Then you can unify the two fractions by simply multiplying the denominators together.
For example, suppose you have an expression like this:
2 3 - + - 4 6
You can combine these fractions by cross-multiplying. After you cross-multiply each fraction's numerator by the other's denominator, your expression will look like this:
(2)(6) (3)(4) ------ + ------ 4 6
See? We simply cross-multiplied. After doing this, we must unify the fractions by multiplying their denominators:
(2)(6) + (3)(4)
-----------------
(4)(6)
The cross-multiplication process is now complete, and we can simplify the fraction by performing the multiplications. Now it looks like this:
12 + 12 ------- 24
We can now perform the addition:
24 -- 24
And finally, now that both the numerator and denominator have been simplified as much as they can, we can perform the division symbolized by the horizontal bar. 24 divided by 24 is 1, so the final answer is simply 1.
Another way to think of creating common denominators is this: Anything multiplied by something, then divided by the same thing, equals the original number. In other words:
xy -- = x y
The multiplication and division operations cancel each other out. If you multiply x by y, then divide the result by y, the final result will be the original value of x. This fact can be very useful when trying to create a common denominator.
For example, suppose you have a fraction like this:
2
2 + -------
x+1
We want to create a common denominator for both sides of this expression. We can simply use x+1 for a common denominator by putting it on the left side, then multiplying the numerator by the same value to make it equal. In other words, we would make the expression look like this:
2(x+1) 2 ------ + --- x+1 x+1
See? We have not changed the actual value of the left side, because we have multiplied it, then divided it, by the same value. Its final value stays the same, yet we now have a common denominator, so we can combine the two fractions together, like this:
2(x+1) + 2 ---------- x+1
Multiplying out the first term, we find this is equal to:
2x + 2 + 2 ---------- x+1
...Which adds up to:
2x + 4 ------ x+1
Another example of using this same rule. Suppose you have a fraction like this:
2 2 --- + --- x+2 x-2
Here, the common denominator is (x+2)(x-2). So, we'll rewrite the expression to reflect that:
2 x-2 2 x+2 --- . --- + --- . --- x+2 x-2 x-2 x+2
We have not changed the original values of the two terms. Notice that we are effectively multiplying the left term by (x-2), then dividing it by that. Since we are multiplying, then dividing it, by the same value, the final value of the expression remains unchanged. Similarly, we multiply the right side by (x+2), then divide it by the same value to leave it the same. The value of this expression has not changed, but we can now express it as a single fraction with a common denominator:
2(x-2) + 2(x+2) --------------- (x+2)(x-2)
Remember, in multiplication, the order of the things you're multiplying doesn't matter, so (x+2)(x-2) is exactly the same as (x-2)(x+2).
If we multiply out the two terms of the above fraction, we could also express it as:
2x - 4 + 2x + 4 --------------- (x+2)(x-2)
Which, when grouped together, could be expressed as:
4x
----------
(x+2)(x-2)
...Since the -4 and the +4 cancel each other out, and 2x + 2x = 4x.
In general, then...
a c ad + cb - + - = ------- b d bd
...because you can get the following by multiplying the top and bottom of each fraction by the other fraction's denominator:
a c ad cb - + - = -- + -- b d bd bd
Conveniently, all of this common denominator stuff is only necessary when adding or subtracting fractions; Multiplying fractions is much more straightforward, because you can simply multiply both sides of the fraction directly. For example, if you wanted to multiply the following two fractions:
3 7 - . - 5 4
...You'd simply multiply the numerators to get 21, and the denominators to get 20. The solution is 21 over 20.
One error that people sometimes make is to assume that you can combine denominators when multiplying the way you can when adding. For example, the following is true:
x y x+y - + - = --- z z z
However, the following is NOT true:
x y xy - . - = -- z z z
The problem is that the denominator needs to be z times itself, or z squared. The correct equation, then, is:
x y xy - . - = -- z z zz
Dividing two fractions is also quite easy if you remember a simple rule. Suppose you had a problem like this:
5 - 4 --- 9 - 2
To divide two fractions like this, you simply invert one fraction, then multiply the two together. So the above expression is equal to:
5 2 - . - 4 9
...Which is 10 over 36. When multiplying or dividing fractions, you only need to remember these simple rules. Only when adding or subtracting fractions do you need to create a common denominator first.
This technique of dividing two fractions can also be used to handle dividing a fraction by a whole number, or dividing a whole number by a fraction. Recall that any number can be made into a fraction by dividing it by 1:
x
x = -
1
So, if you have to divide a fraction by a whole number, like this:
5 - 4 --- 9
...then you can turn the bottom number into a fraction by dividing it by 1, which gives us:
5 - 4 --- 9 - 1
...and then we can use the earlier rule for transforming a 4-layer fraction to turn this into a multiplication of ordinary fractions:
5 1 - . - 4 9
The same works for dividing a whole number by a fraction:
5
5 -
--- 1 5 9
4 = --- = - . -
- 4 1 4
9 -
9
Another very important trick for simplifying fractions is the practice of cancelling out common factors. This refers to the fact that if there is a multiplicand both above and below the fraction line, you can cross it out and eliminate it from the fraction. For example, if you have a fraction like this:
13x --- 7x
...Then you can simply cross out the "x"s, both above and below the line, leaving you simply with 13 over 7.
This trick is where factoring expressions really becomes handy. Remember, to factor something is simply to express it in a multiplied-out form. So, suppose you had a fraction like this:
12x --- 8y
At first, it seems like there are no common elements in this fraction which can be cancelled out. But in actuality, both of the coefficients in this fraction (that is, the numbers which are multiplied by the variables) have common factors. The greatest common factor (GCF) of 12 and 8 is 4, so you can use this GCF to simplify the fraction by using 4 to multiply:
4 . 3x ------ 4 . 2y
...And now we can see that the common factor of 4 is both above and below the line, so we can simply delete it, leaving us with:
3x -- 2y
This sort of thing is commonly done with exponents. Remember that x^5 (x to the power of 5) is simply 5 "x"s multiplied together, i.e. xxxxx. So, if you have an expression like this:
x^7 --- x^5
...Then that is actually the same as this:
xxxxxxx ------- xxxxx
...And now you can cross off the five "x"s on the bottom, as well as five of them on the top, leaving you with just two. So:
x^7 xxxxxxx --- = ------- = xx = x^2 x^5 xxxxx
And, similarly, if you have this:
x^2 . y^4 --------- x . y^7
...Then you actually have this:
xxyyyy -------- xyyyyyyy
...And so, you can remove one x from both sides, and four ys.
x --- yyy
One other thing worth knowing about fractions:
y xy
x . - = --
z z
If you take a regular number and multiply it by a fraction, this is the same as if the number were part of the fraction's numerator. So, if it's more convenient, you can just combine the number as part of the numerator, and similarly, if you need to break up a fraction, you can take any term out of its numerator and multiply them by the fraction separately. This makes sense in light of how we multiply fractions, because any whole number can be expressed as itself over 1. Anything divided by 1 remains the same, so x over 1 is still x. Thus, if we change x to x over 1, we get:
x y xy - . - = -- 1 z z
...Which makes perfect sense, because we can multiply x by y to get xy, and anything times 1 remains unchanged, so 1 times z is z.
A radical is a number which is expressed as the square root of something. For example, if you write a 4 and draw a square-root sign over it, that's a radical. The solution to this particular radical happens to be 2, because 2 is the square-root of 4. Unfortunately, many radicals aren't this simple.
In addition to square roots, you can have roots of almost any other number. For example, a cube root is the third root. This would be denoted by writing a little number 3 above the left side of the root sign. The cube root of 64, for example, is 4, because 4x4x4 (4^3) is 64. Similarly, you can put any root number you want over the root sign, although basic algebra usually doesn't go beyond the second (square) and third (cube) roots.
Radicals are interesting because often they are irrational, meaning they cannot be expressed as a rational number, i.e. a fraction. This means that the only way to express them is as a root of something. A simple (and commonly-cited) example is the square root of 2. What is the square root of 2? Well, it's a number that actually exists, and it's a bit more than 1.4 and a bit less than 1.5, but it can't actually be written out as a decimal, or a fraction, or any other way that regular math can represent it, other than to just write a number 2 and put a root sign over it. That's the only way to represent this value.
A similar concept is imaginary numbers. The classical imaginary number in math is the square root of -1, which is so commonly-used in algebra that it is commonly represented as i. i is the square root of -1. Unlike the square root of 2, which really exists but can't be written in our decimal number system, the square root of -1 is impossible. In fact, the square root of any negative number is impossible, because any number times itself is never less than zero. (This is one of the rules of working with integers, remember? A positive number times a positive number is positive, and a negative number times a negative number is also positive. So any number squared is positive, unless it's zero, in which case it's still not negative.) The square root of -1 doesn't exist. It can't. And yet, you can still represent it by drawing a root sign over -1, and mathematicians have still crowned this value as i. Perhaps surprisingly, however, once you get used to this idea, you might find that working with i is actually considerably less complicated than most subjects in college algebra.
Another nice thing about radicals is that they're wonderfully transformative. Radicals can be combined and split with ease, because the square root of x times the square root of y = the square root of x times y. Or, to put it in notation more readable to computer programmers:
sqrt(x) * sqrt(y) = sqrt(x*y)
If you have two separate radicals that need to be multiplied, you can very easily multiply them by just muliplying their radicands (the numbers under the root sign), and then putting a root sign over the result. For example, sqrt(5) * sqrt(7) = sqrt(35). We don't know the square root of 5, 7, or 35, and we don't have to know or care. We can still easily multiply their radicals together using this property.
Also note that the root of something, times the same root of that same thing, equals the value under the root sign. For example:
sqrt(2) * sqrt(2) = 2
We still can't represent the square root of 2 any other way, but we do know that if you multiply it by itself, it equals 2.
If you are using radicals in equations, a typical way of dealing with the radicals in the equation is to simply square them to get rid of them. For example, suppose you have an equation like this:
sqrt(x+5) = sqrt(y-7)
Remember, any operation done on both sides of an equation doesn't change the value of the equation; So, you can simply square both sides of this equation to eliminate the radicals entirely. The result becomes, simply:
x+5 = y-7
A similar trick can be used to rationalize the denominator of a fraction. To rationalize a radical means to express it in non-root form, as a rational number. If you have a fraction which has a radical for a denominator, this denominator can be very easy rationalized by multiplying both sides of the fraction by the denominator. For example, suppose you have a fraction like this:
sqrt(3) ------- sqrt(2)
To rationalize the denominator of this fraction, multiply both sides of the fraction by the root of 2:
sqrt(3) . sqrt(2) ----------------- sqrt(2) . sqrt(2)
Since a radical times itself equals the radicand, the denominator becomes 2, while the numerator can be simplified to the root of 3 times 2, which is 6.
sqrt(6)
-------
2
Exponents, to the extent that most people understand them, are pretty simple. You probably know, for example, that 2 to the power of 3 means three 2s, all multiplied together: 2x2x2, which is equal to 8. Straightforward, right? Unfortunately, there are several different kinds of exponents, and the rest are not as simple.
First of all, what about a power of zero? Something raised to the power of 0 might seem like it should be 0. After all, zero is nothing, right? But actually, anything raised to the power of 0 equals 1. Just because.
On top of that, what if you have a negative exponent? This should seem impossible; How can you multiply something by itself a negative number of times? Well, you can't. Rather, a negative exponent indicates that the answer is a fraction. When you see a negative exponent, this actually represents 1 divided by the positive result of the exponent. For example, what's 2 to the power of -3? According to the negative exponent rule, it's 1 divided by 2 to the power of 3. 2 to the power of 3 is, recall, 8, so 2 to the power of -3 is one-eighth. Weird, huh?
Sad to say, it gets even worse. What if you have a FRACTIONAL exponent? Here it gets a little crazy, so be prepared to think about this one for a while. Suppose you have an expression like eight to the power of two-thirds. Two-thirds is 2/3. So you've got a number 8, and next to it, as an exponent, you've got 2 over 3. How do you deal with something like that?
When working with a fractional exponent (often also called a rational exponent), the numerator of the exponent (the number at the top of the fraction) is the power: The number of times you actually multiply the base. The denominator (the lower part of the fraction) becomes the root number. In other words, eight to the power of 2/3 means eight to the power of two, to the root of three. Eight to the power of 2 is 64, and 64 to the root of 3 is 4. Hence, 8^2/3 = 4.
"Matrices" is the plural of "matrix". Unfortunately (or fortunately, depending on how you look at it), this kind of matrix has nothing to do with the movies. Rather, this is a mathematical matrix.
A matrix is simply a grid or array of values. (These values can be numbers, variables, expressions, or anything that corresponds to some kind of numerical value.) In fact, that basic idea of a matrix is very simple. It really is exactly that: A grid of numbers. For example, the following is a matrix:
[ 2 18 ] [ 5 37 ]
And this is also a matrix:
[ 5+a 16 c ] [ 97 b 9 ] [ 6/a 2 4 ]
Remember, a variable (such as a) which represents a number is still a value that can be used in a matrix.
Understanding the basic concept of matrices is pretty simple. Performing math operations with them is a little more complicated. Matrices can be added, subtracted, multiplied, and divided, just like regular numbers. However, the procedures for doing so are not perfectly straightforward.
To add a matrix to another matrix, you simply add the values from each entry of the matrix together. Subtraction works similarly. So, if you consider the following two matrices...
[ 2 4 ] [ 8 3 ] [ 5 3 ] [ 7 2 ]
...Then their sum is:
[ 10 7 ] [ 12 5 ]
Note that in order to add or subtract matrices, they must be the same size. In this example, the matrices added both have two rows and two columns. If the two matrices were of different sizes, they could not be added or subtracted.
Adding and subtracting matrices is a pretty straightforward and intuitive process. Matrices can also be multiplied. However, multiplying two matrices is a very different process from adding them.
When multiplying matrices, the first thing you need to know is that the commutative law for multiplication no longer applies. The commutative law for multiplication is what states that x times y is the same as y times x. In other words, no matter what order you multiply things in, you come out with the same result. Well, this law isn't true for matrices; x times y may NOT necessarily be the same as y times x.
Having said this, let's proceed with how to multiply matrices.
First of all, in order to multiply two matrices x times y, matrix x must have the same width as the height of matrix y. In other words, the number of columns in matrix x must equal the number of rows in matrix y. Read that again, in case you didn't catch it the first time. If this condition is not satisfied, the matrices cannot be multiplied in terms of x times y (although y times x may be possible, if the condition is satisfied in this order).
If you have a matrix multiplication operation which can be performed, then the resulting matrix has the height of matrix x, and the width of matrix y.
To determine the value for row a, column b of the product matrix, take row a from matrix x, and column b from matrix y. For each entry in these two series of numbers, multiply the two numbers together. Add up the results of all these multiplications, and the result is the value for that entry in the product matrix.
Did you get all that? This process is so messed up that if you didn't understand what you just read, don't even bother trying to read it again. Let's just do an actual multiplication of two matrices, and hopefully you'll understand how it works after that.
Suppose this is our matrix x:
[ 1 2 ] [ 3 4 ] [ 5 6 ]
Further suppose that this is our matrix y:
[ 10 11 12 13 14 ] [ 15 16 17 18 19 ]
...And we want to find out what x times y is. This operation can be performed, because the width of x is equal to the height of y. (Both dimensions are 2.) x times y is possible, but y times x is not.
Our product matrix has the height of matrix x (3), and the width of matrix y (5). If we fill it in with "x"s to indicate unknown values, our product matrix looks like this right now:
[ x x x x x ] [ x x x x x ] [ x x x x x ]
Now, let's start at the beginning, and try to calculate the value for row 1, column 1 here. To do this, we take all the values from row 1 of matrix x (1 and 2), and multiply them with their corresponding values from column 1 of matrix y (10 and 15). The resulting multiplications are 1 times 10, and 2 times 15.
1 * 10 = 10
2 * 15 = 30
Now we add up the results of all these multiplications. 10 plus 30 is 40, so the value for row 1, column 1 is 40.
[ 40 x x x x ] [ x x x x x ] [ x x x x x ]
Doing the other operations (or using a calculator to do them), we come up with a final product matrix of:
[ 40 43 46 49 52 ] [ 90 97 104 111 118 ] [ 140 151 162 173 184 ]
Why are matrices multiplied in this horribly clunky way? There *is* a reason. The reason is basically that this method of multiplication is the most useful for the work that is actually done with matrices in math.
A scalar is simply a value that represents magnitude. For example, if you are describing how tall someone is, you'd use a simple number to express their height. On a bar graph, the bar representing a person's height is one-dimensional; it can only be longer or shorter. Natural numbers that we work with every day are typically scalars.
By comparison, a vector is a value possessing both magnitude and direction. A perfect example of where you might want to use a vector is when expressing wind speed. The wind has a speed, but it also has a direction. A vector could be used to represent both the direction and the magnitude (speed) of the wind. Graphically, vectors are graphed as arrows, with the head of the arrow pointing in the appropriate direction, and the line of the arrow drawn longer or shorter to represent greater or lesser magnitudes, respectively.
In writing, vectors are often described by the coordinates of their endpoint. For example, a vector in "2-space" (two-dimensional space, i.e. a flat plane) might be described as 5,2. This is simply a point in the Cartesian coordinate system (you know, the one that uses x,y coordinates), and the vector extends from the origin (which is point 0,0 on a graph) to point 5,2. Vectors in 3-space (three-dimensional space) are described the same way, except they have a third coordinate for the third dimension. So, you might see a vector described as 5,2,7, which means it extends from the origin 5 units along the x axis, 2 along the y axis, and 7 along the z axis.
Vectors are sometimes also made into one-dimensional matrices. So, for example, the three-dimensional vector mentioned above could be made into the following matrix:
[ 5 ] [ 2 ] [ 7 ]
A quadratic equation is a very specific and important format of equation; It takes the following form:
ax2 + bx + c = 0
...Where x is a variable and a, b, and c are constants. Note, also, that the "2" there is actually an exponent.
A function is basically a "math machine", which takes a particular variable for input, and produces some value for output.
A function has a domain and a range. When graphing functions (as is often done in calculus), the domain is the horizontal axis, and the range is the vertical axis.
y = x is a linear function, because if you graphed it, the graph of the function would look like a straight line. Another linear function is y = x2. (x2 meaning x squared.)
Like any other line, linear functions have slopes. The slope of y = x is 1, while y = x2 has a slope of 2.
The slope, then, can be defined as the rate of change of y with respect to x.
A simple example of a function which forms a parabola on a graph is:
y = x^2
That is, y equals x to the power of 2, or, y equals x squared. This function, plotted on a graph, starts out at coordinates 0,0, and from there a parabola is formed that opens upward, the lines arcing ever more steeply upward. When x is 1, y is 1... So far, that's basic enough, but then when x is 2, y is 4, and by the time x becomes 3, y is already 9. This is why the lines of the parabola move upward so quickly.
A somewhat similar function which demonstrates an interesting effect is this:
y = x^3
It looks almost the same as the previous one, and you might think, at first glance, that it would look similar if plotted on a graph, except that the lines would turn upward even more sharply. However, try actually calculating the values of the points and you'll soon realize that this graph is not a parabola at all; It's a curve. The reason is that the values on the left side of 0 are values where x is negative, and since this negative number is being multiplied by itself an even number of times, it remains negative. A negative number multiplied by itself only once becomes a positive number, which is why the left half of the previous function went up; The left half of this function goes down, because when the positive number is multiplied yet again by the original negative number, it becomes negative again. So this function is basically a parabola with one half inverted, so that it becomes not a parabola but a simple curve.
Functions are declared using the following math syntax:
f(variable) = functioncode
...Where variable is the name of the variable the function is acting on, and functioncode is the expression for calculating the result of the function. For example, you could define our y = x2 function like this:
f(x) = x ^ 2
What this line means is that when this function acts upon its input, the output is simply the input squared. Building on this, with respect to the same function, you could write a line like this:
f(5) = 25
...Which means that if the function gets 5 for input, it will produce 25 for output.
Apologies for the textual nature of these descriptions. Trigonometric functions like the sine and cosine should really be expressed graphically, but I'll try to be picturesque with my descriptions, and if you follow along, you should be able to build these images in your mind (or on paper) as you read.
Imagine, if you will, a triangle.
Still with me? Now suppose that this triangle is a right triangle, which is a triangle which has one right angle, i.e. one 90-degree angle. (It's geometrically impossible to make a triangle with more than one 90-degree angle, by the way.)
Okay, we're really cooking now. Let's position this theoretical triangle so that the right angle is in the lower-right corner of the plane that this triangle exists in. If you do this, then you'll have a triangle with one right angle in the lower-right, and two acute angles, one to the left of that right angle, and the other above the right angle. Not only that, but you'll have the triangle's longest side (also known as the hypotenuse) on the upper-left part of the triangle.
Now that we have this triangle, let's talk about the relationship between the leftmost angle in the triangle (which will be an acute angle of some kind), and the rightmost side of the triangle (which will be vertical). Since the angle on the left will be the input into the sine function, let's call that angle's value (in degrees) x. Of course, this angle must be less than 90 degrees, so let's assume that we're working with an angle here that can range from around 0 to 89 degrees or so.
It should be clear that if you increase x (make the left angle wider), the right side of the triangle will get longer. If you decrease x (make the left angle narrower), the right side gets shorter. If you make x really small, the triangle flattens into an almost horizontal line. If you make x huge, the triangle stretches out vertically.
Not only does the value of x change the length of the right side of the triangle; it also changes the ratio of that side's length relative to the hypotenuse. This is the essence of what the sine is.
The sine is the ratio of the right side's length, relative to the hypotenuse.
What this means is that the sine expresses how long that right side of the triangle is, relative to the hypotenuse. If the sine is 0.5, that means the right side is half as long as the hypotenuse. If the sine is 0.2, that means the right side is one-fifth as long as the hypotenuse.
If you make x really small, so that you have a triangle that's not very high, then the right side of the triangle is short compared to the hypotenuse. That means the sine gets small, too. If you make x big, so that the triangle towers high, the right side is almost as long as the hypotenuse, and then the sine is close to 1. The sine can never get higher than 1 because the hypotenuse is by definition the longest side of the triangle, and a sine of more than 1 implies that the right side of the triangle is actually longer than the hypotenuse. However, you can have sines that get really close to 1, and in fact, if you make the value of x equal to 90, then the triangle turns into a straight vertical line. In this scenario, the hypotenuse has exactly the same length as that right side of the triangle, and so the sine is 1. Thus, if x is 90, then the sine is 1. If x is 0, then the sine is 0. If x is 30, then the sine is 0.5, meaning that the right side of the triangle is half as long as the hypotenuse when the angle on the left is 30 degrees.
That's really it. That's what a sine is. Of course, the angle represented by x doesn't have to be on the left, and the side which gets compared to the hypotenuse doesn't have to be on the right; I just described them that way to form an image in your mind. You can rotate the triangle any which way you want, and the sine will still work.
The sine can also be expressed in terms of a circle, and since trigonometric functions are often used with circular shapes, I'll try to explain how the circle analogy works as well.
Imagine, if you will, a circle. Further suppose that this circle is placed in a Cartesian coordinate system (you know, the kind which uses x,y coordinates to place stuff on a two-dimensional plane), and that the center of this circle is exactly on the origin of this Cartesian coordinate system (in other words, the center of the circle is at (0,0)). On top of all this, imagine that the circle is exactly one unit in radius. Thus, the very highest point on the circle would be at (0,1), the lowest point on it would be (0,-1), the leftmost point would be (-1,0), and the rightmost point on this circle is (1,0). If you can envision this, you've got the makings of a sine function. This circle, by the way, is mathematically called a unit circle.
Moving on, imagine that there is a line extending to the right from the center of this circle. It's a perfectly straight horizontal line. It is the graph of the function y = 0.
Now imagine that you are drawing a second line in this circle. Again, the line begins at the center of the circle, but this time, you can pick any direction you want to point the line in.
The angle between these two lines is the x input for the sine function. There's a trick to this, though: The angle between the two lines must be measured in a counter-clockwise direction, beginning from the first line and going around from there. For example, if you draw your second line going straight down, the angle formed by the two lines looks like it's 90 degrees. However, it's only 90 degrees if you do the angle going clockwise; Since this angle must be measured COUNTER-clockwise, the angle in this case would actually be 270 degrees, not 90. Get it?
If you've got all this down, then you're almost done. The sine of the angle x is the y-coordinate of the point where the second line meets the circle. That's it. It's that simple.
For example, suppose that x is 90 degrees. This means that you have a perfectly vertical line going up. It meets the circle at the very top of the circle. Because the top of the circle is at coordinates (0,1), the y-coordinate where the second line meets the circle is 1. Thus, the sine of 90 is 1.
If x is 180 degrees, then the second line goes in precisely the opposite direction from the first line. It meets the circle at coordinates (-1,0), so the sine of 180 is 0.
If x is 270 degrees, then the second line goes straight down. It meets the circle at (0,-1), so the sine of 270 is -1.
There you have it. The sine function takes a number as its input, and its output can be anywhere from -1 to 1. It's actually remarkably easy once you think about it several times.
If you can understand the sine, then the cosine should be pretty easy to understand. It's really just the complement to the sine.
Imagine, again, our right triangle with the right angle in the lower-right corner.
When we spoke of the sine, we concentrated on the right side of the triangle. What we didn't talk about was the BOTTOM of the triangle. The poor, neglected bottom side of the triangle changes as we change x, too. Now it's going to get some attention, because it's the subject of the cosine.
Think, again, what happens to the side when x changes. This time, when x gets smaller, the bottom side of the triangle gets bigger. If x gets bigger, the bottom side of the triangle gets smaller.
The cosine is the ratio of that bottom side to the hypotenuse. It's the same as the sine, except with the sine, we were talking about the right side of the triangle. Now, with the cosine, we're talking about the bottom side. In trigonometric terms, with the sine we look at the side opposite (because it's the side of the triangle opposite from the angle), and with the cosine, we talk about the side adjacent (because it's the side that's adjacent to the angle).
If x gets small enough that the triangle flattens into a flat horizontal line, then the bottom side of the triangle has the same length as the hypotenuse, and the cosine is 1. If x gets so big that the triangle becomes a vertical line, then the bottom side has no length at all anymore, and the cosine becomes 0. So, the cosine of 0 is 1, and the cosine of 90 is 0.
In terms of the circle we were talking about, the cosine is the x-coordinate of the point where the second line meets the circle.
If x is 90, then the second line goes vertically up. It meets the circle at (0,1), so the cosine of 90 is 0.
If x is 180, then the second line meets the circle at (-1,0). The cosine of 180 is -1.
If x is 270, then the second line meets the circle at (0,-1). The cosine of 270 is 0.
Yet again, let's imagine our right triangle with the right angle in the lower-right corner.
The tangent is another ratio of sides. This time, it's the ratio of the right side to the bottom side.
If x gets small, the bottom side lengthens out, and the right side gets shorter. If x gets large, the bottom side gets small, and the right side gets longer.
If x is 0, the triangle flattens into a horizontal line. Since the right side has a length of zero, the tangent of 0 is 0, since 0 divided by anything is 0.
If x is 90, the triangle turns into a vertical line. At this point, the bottom side has a length of zero. Because we're dividing the length of the right side by zero, we get a divide-by-zero error. Therefore, the tangent of 90 is not defined.
Going back to our unit circle, you take the point where the second line meets the circle, and this time, you divide the point's y-coordinate by its x-coordinate to get the tangent.
If x is 90, the second line meets the circle at (0,1). The tangent is 1 divided by 0, which is undefined.
If x is 180, the second line meets the circle at (-1,0). The tangent is 0 divided by -1, which is 0.
If x is 270, the second line meets the circle at (0,-1). The tangent is -1 divided by 0, which is undefined.
At this point, you might have actually guessed this one. That's right: The cotangent is the ratio of the bottom side to the right side.
In terms of the circle, the cotangent is the x-coordinate divided by the y-coordinate.
If x is 90, the second line meets the circle at (0,1). The cotangent is 0 divided by 1, which is 0.
If x is 180, the second line meets the circle at (-1,0). The cotangent is -1 divided by 0, which is undefined.
If x is 270, the second line meets the circle at (0,-1). The cotangent is 0 divided by -1, which is 0.
Okay. We're almost done with the fundamental trigonometric functions. But you may have noticed that we don't have any functions yet to described the ratio of the hypotenuse to the other sides.
That's right. The secant is the ratio of the hypotenuse to the bottom side. It can also be expressed as the reciprocal of the cosine, meaning the secant is equal to 1 divided by the cosine.
If x gets small, the bottom side gets longer, so the hypotenuse isn't as large compared to that bottom side anymore. If x goes all the way down to 0, then the secant is 1. As x increases, however, the secant increases too, because the hypotenuse gets longer than the bottom side. Finally, when x is 90, the length of the bottom side diminishes to zero, and so you have, again, a divide-by-zero error, meaning the secant of 90 is undefined.
Finally, the cosecant, as you probably guessed, is the ratio of the hypotenuse to the right side of the triangle. It can also be expressed as 1 divided by the sine.
The definitions for all of these functions are simple: They're simply their original functions in reverse.
For example, we know that the sine of 90 is 1. Therefore, the inverse sine of 1 is 90.
The same idea applies to the inverse cosine and inverse tangent.
A logarithmic function is really just a re-arranged exponentiation. You know how 2^4 = 16? Well, log2 16 = 4.
The number which comes right after the "log" is called the base of the logarithm. In properly typeset writing, the base number should be written in subscript. Since I'm basically writing ASCII here, I just write it as a number immediately following "log", with no space. A space separates the number which the logarithm is operating on.
As you can see, the logarithm is basically just asking "What power do I need to exponentiate the base by to get this number?" The resulting exponent is the output of the logarithm function.
It's common to use a logarithm with a base of 10. This is called the common logarithm, and if no base number is specified, it's assuming that we're using this base of 10. So, log 100 = 2.
The usual rules that are taught for logarithms are as follows (note that these apply regardless of what base is used, although the same base must be used for each instance of the logarithm function in the equations below):
log(xy) = log(x) + log(y)
log(x/y) = log(x) - log(y)
log(x^y) = y log(x)
Also usually taught in this context are the following two non-equations that students often make when working with logarithms:
log(x+y) DOES NOT EQUAL log(x) + log(y)
log(x-y) DOES NOT EQUAL log(x) - log(y)
The natural logarithm is simply a logarithm which uses e for a base.
What's e, you ask? It's another mathematical constant, like pi, that goes on forever and cannot be completely expressed as a decimal. You can probably get by with using a value of 2.71828182845904523536 for e.
The hyperbolic sine function takes an input variable x and calculates a result according to the following formula:
(e^x - e^-x)/2
The hyperbolic cosine function takes an input variable x and calculates a result according to the following formula:
(e^x + e^-x)/2
The hyperbolic tangent is the hyperbolic sine divided by the hyperbolic cosine.
Everything below this point is in the realm of calculus. Limits, tangents, and integrals are the essentials of calculus math, and they are all found below. Before you journey into this realm, it is crucial that you have a thorough understanding of algebra; Calculus expands largely on algebra, and it is important that you are very comfortable doing complex algebraic manipulations before you can begin to work with and understand most calculus concepts.
There are two main types of calculus: Differential calculus and integral calculus. Differential calculus deals with differentials and derivatives, while integral calculus concerns itself with integrals. Generally speaking, derivatives tend to be an easier concept to teach and understand than integrals, so people who are learning calculus usually learn about derivatives first. However, limits are the centerpiece of both derivatives and integrals, so before you can understand either of these two main branches of calculus, you must understand mathematical limits.
Limits are the first step to understanding all fundamental calculus. They are the key to solving both derivatives and integrals.
When you work with university-level concepts, you often run into concepts which are not clearly understood or explained, but rather which must be understood vaguely, as if you sort of have an idea of what they represent, but not exactly. The limit is one of those concepts. Quite simply, instead of being the exact solution for a mathematical formula, a limit is what a mathematical formula is really close to.
When you solve mathematical problems, you usually want to come up with an exact answer. 1 + 1 is exactly 2, no more and no less. But sometimes you come across a problem which cannot be solved exactly; You can come up with a pretty good idea of what the answer is, but this answer is not exact, for whatever reason. This is not the same as the "estimating" you may have done in primary-school math, where you see (for example) a picture of a beach and are asked to simply take a guess as to how many grains of sand are on the beach; Calculating limits is actually an exact science like solving equations, not simply a matter of guessing, but a limit is not always a precisely true answer.
Sometimes limits can be solved by simply solving their expression. For example, suppose that you have the expression x + 4, and you want to find the limit of this expression as x approaches 1. The closer x gets to 1, the closer the result of this expression will be to 5. If you made a list of some values close to 1, and then calculated the results of each of these, the list might look something like this, with values for x on the left, and the resulting values of the expression on the right:
0.9 4.9 0.99 4.99 0.999 4.999 0.9999 4.9999 1.1 5.1 1.01 5.01 1.001 5.001 1.0001 5.0001
You can see that as x gets closer to 1, the result of x + 4 gets closer to 5.
Of course, this may seem rather silly to you; Why go through all this trouble when you can just directly add 1 + 4 and get 5? Well, you can do that for this particular expression, but there are some expressions which you can't calculate exactly as they are.
Limits are typically used in expressions which involve division by zero. As you should well know, dividing something by zero is mathematically impossible; In mathematical terms, division by zero is undefined. However, suppose you have an equation like 2 / x, where you know that x is zero. This expression is undefined if x is zero. But suppose you want to come up with an idea of what the expression is close to.
If you made x into something that's close to zero, but not exactly zero, you might be able to come up with a real answer. Suppose you made x into 0.0000000001. You could calculate the solution to the expression then. After that, you might make x into 0.000000000000000000000000000000001, a value that's even closer to zero, and calculate the answer again. As you do this, you might notice that as x creeps closer and closer to zero, the answer creeps closer and closer to a certain value. This value, although it is never precisely reached, could be considered the "limit" of this expression. In somewhat theoretical terms, you could say that as x becomes infinitely close to zero, the answer becomes infinitely close to that limit. This limit can be taken as the "answer" to the equation.
In the example above, if you calculate it out, you'll see that as x gets closer to 0, 2 / x just keeps getting bigger. It becomes apparent that the closer x comes to 0, the bigger the answer becomes. We can keep making x get closer and closer to 0, and the answer will just keep getting bigger and bigger. In this case, we say that the limit of the expression is infinity. (This isn't STRICTLY true, since the result of the expression will be negative if x happens to be negative, so if you want to be picky now, you can say that the absolute value of this expression as x approaches 0 is infinity.)
As you may anticipate, however, trying to guess the value of a limit by bringing the variable closer and closer to its intended point doesn't always work. In the simple examples we have viewed so far, it is easy to guess where the answer will eventually lead, but not all expressions come up with a nice simple value for their result. In fact, in university calculus, many expressions have answers too complicated to simply guess at in this way. In real-world, practice, limits are arrived at by performing algebraic manipulation on an expression until it is no longer undefined. This is the standard way in which limits for expressions are determined. For example, suppose you had a fraction like this:
(x+1)(x-1) ---------- (x-1)
...And you want to find out what this expression would equal when x is 1. Often when simplifying an expression like this, when you know the actual value of the variables, you can simply substitute those values in the expression (so, in this case, you'd simply change every x in the expression into a 1). However, in this case you can't do that, because if x is 1, then the denominator of the fraction becomes zero (since x-1 would evaluate to zero), which means solving the fraction would become impossible. In this case, we must express the "solution" of this problem as a limit.
First, as with any other algebraic expression, we'd start by simplifying the expression. In this case, we have the same multiplied polynomial above and below the division line: x-1. As you might recall from algebra, since this same polynomial is multiplied both above and below the line, we can simply cross both occurrences of it out. (See why remembering algebra is important here?) So our fraction would become simply this:
(x+1) ----- 1
...And since the denominator is now 1, we can simply omit it, and express the expression as x+1. Remembering that we're trying to evaluate this expression given that x=1, we can now very easily see that x+1 equals 2. Thus, 2 is our final answer to our original expression. We do NOT say that the expression is equal to 2 when x is 1; That is incorrect, since it is still a divide-by-zero error. Rather, we say that the limit of the expression, as x approaches 1, is 2. If you set x to 0.999999999999, or 1.000000000000000000000000000000000000001, the result of the expression will be very close to 2. As x becomes closer and closer to 1, the expression will come closer and closer to 2. However, the expression never equals exactly 2.
The tangent is the limit of a secant line.
The formula for the slope of a tangent is:
lim x -> a ((f(x) - f(a)) / (x - a))
...Where a is the value of x where you want to find the tangent. f(x) represents the result of performing the function on the value of x, and similarly, f(a) represents the result of performing the function on the value of a.
As a simple example, suppose that you have the following function:
y = x + 2
...And you want to find the slope of the tangent at the point on this graph where x is 4. Because the variable a in the formula represents the value of x, we set a to be 4. The equation to find the tangent, then, looks like this:
lim x -> 4 ((f(x) - f(4)) / (x - 4))
...Keeping in mind that the function is x + 2, and knowing that 4 plus 2 is 6 (so f(4) is 6) we can simplify this formula as follows:
lim x -> 4 ((f(x) - 6) / (x - 4))
We can also remove the first "f" by simply expanding it to the full function code for x:
lim x -> 4 (((x + 2) - 6) / (x - 4))
x + 2 - 6 is the same as x - 4. So...
lim x -> 4 ((x - 4) / (x - 4))
The solution to this limit is 1, because something divided by itself is 1. Although the answer is undefined when x is exactly 4 (because that makes the divisor 0, creating a divide-by-zero error), the answer is 1 for any other value of x. If x is 3.9, the answer is 1. If x is 4.1, the answer is 1. For that matter, if x is 3.99999 (a number very close to 4), the answer is still 1, and is x is 4.00001 (another number very close to 4), the answer remains 1. Of course, the answer is also 1 if x is eleventeen quintillion, but that's beside the point. (Don't send me angry letters pointing out that "eleventeen" is not a number.)
Thus, the slope of the tangent for the function y = x + 2 is 1.
The derivative is one of the most important concepts in basic calculus. It is a concept that you will be working with a lot if you study calculus. Thus it is critical to calculus studies that you understand the concept of the derivative. However, the derivative builds upon some other important mathematical concepts, especially limits, functions, and tangent lines. Therefore, it is crucial to the understanding of derivatives that you understand these concepts well first, as stepping-stones to the goal of understanding derivatives. If you do not understand these concepts, go back and learn them well before you start on derivatives.
A derivative is actually a function. In fact, it is a function derived from another function. The derivative is expressed as a function with respect to a variable (usually x, which represents the horizontal axis on the graph of a function).
Conceptually, the derivative is actually a pretty easy and intuitive concept to understand. The derivative simply expresses the slope of its parent function. Every line on a two-dimensional plane has a slope at every point (unless the line is vertical, in which case the slope at that point is considered to be either infinity, or undefined, depending on who you ask). If the line is a straight line all the way through, it has a constant slope. But what if the line curves around? Then the slope of the line will be different at different points. Well, the purpose of the derivative is to express the slope of a line at ALL points; for every value of x that goes into an originating function, the derivative for that same value of x will tell you the originating function's slope at that point.
The derivative of f(x) is written as f'(x). This is spoken as "f prime x" (the tick mark is read as "prime"). Graphically, the derivative represents the slope of a tangent line on the graph of f at point x.
The formula for the derivative of f(x) is:
f(x+h) - f(x)
f'(x) = lim h -> 0 -------------
h
...Where f represents the function which you are trying to find the derivative for, x represents the horizontal point within f which you are trying to find the vertical value for, and h is just a part of the formula which happens to be approaching zero.
Notice that if you simply make h equal zero, this formula will result in a divide-by-zero error, which is why you need to use the limit instead. Since the very definition of a derivative involves a divide-by-zero, it should be clear that you need to understand using limits before you can work with derivatives.
Having said that, however, in all fairness, the derivative is typically not actually calculated using the above formula. The formula is the "official" definition of a derivative, but in reality, when you take introductory calculus, you're given a set of basic rules which define most of the operations you need to know for calculating derivatives. In light of this, let's take a look at a few basic rules and examples of derivatives.
The derivative of a constant is zero.
The derivative of the function y = x is 1. This is because the function has 1 as a rate of change; Every time x goes up by 1, y goes up by 1 as well. The derivative of this function looks like a flat horizontal line; It is always at a y value of 1, no matter where x is.
The derivative of the function y = 2x is 2. For every time that x increases by 1, y increases by 2. Once again, the derivative is a flat line, always at a y value of 2.
The derivative of x^2 is x*2. Graph these out and see how they relate to each other.
The derivative of x^3 is 3*x^2. Again, graph these out and notice how the derivative indicates the rate of change for the function: The derivative is in fact a parabola. As the line of the original function starts to come up on the left half of the graph, it is slowly losing its upward velocity; As it approaches zero, it slowly starts to bend more to the right instead of up, because it is moving up more slowly. The parabola that is the derivative reflects this; It starts out being very high, and rapidly comes down, because the speed of the function is slowing down, and the derivative is really just a reflection of the function's speed. Notice that although the derivative moves sharply downward, it never goes below zero; This is because the function itself never actually goes downward. If it started going down, the derivative would have to go below zero to reflect negative velocity. The function and its derivative finally meet exactly at zero, since at this point, the function's speed is zero (it is horizontal at this point, neither moving up nor down), and so the derivative is also zero to reflect this. Finally, as the function moves to the right, it starts moving upward, and so the derivative moves upward with it to reflect this.
There is another notation used with derivatives which I personally find annoying and unintuitive, but which you'll see a lot, and which you therefore need to be familiar with. It's the practice of notating a derivative as what looks like a fraction. This clasically takes the form of dy/dx, which means "the derivative of y with respect to x". Understand that a derivative, like any other function, represents some output variable's response to an input variable. If f(x) = y, then whatever x is will dictate, based on the function's rules, what y ends up being. The same is true with a derivative: The derivative takes some input value like x, and gives some output value like y. What dy/dx means is not a division operation; it simply means the derivative of y with respect to x. This notation, once you get used to it, can actually be handy because it tells you, at a glance, what both the input function and the output name is; if you see "da/db", that means the derivative representing the slope of a graph in which a is the vertical axis and b is the horizontal axis. This notation for derivatives is called Leibnitz notation.
We have seen how to get the derivative for a single function, but how would you determine the derivative of two functions added together? For this, we use the sum rule. The sum rule is used to determine the derivative of two functions added together. (Bear in mind that a "sum", in the mathematical sense, is the result of an addition. For example, 5 is the sum of 2 plus 3.)
The sum rule reads as follows:
The derivative of the sum of two functions is the derivative of the first function plus the derivative of the second function. Or, to express this as a mathematical equation:
d(a+b) = da + db
In more brief words:
The derivative of a sum is the sum of the derivatives.
So says the sum rule. Similar rules exist for subtraction (the difference rule), multiplication (the product rule), division (the quotient rule), exponentiation (the power rule), and combinations of these operations (the chain rule).
Let's calculate a derivative using the sum rule. Suppose you have a function like this:
x + 5
Now we want to find the derivative of this, right? Right. Well, it's apparent that the function we're looking at is a sum. So, since the derivative of a sum is the sum of the derivatives...
The derivative of (x + 5) is the derivative of x, added to the derivative of 5.
d(x + 5) = d(x) + d(5)
Going back to our basic rules for derivatives, we recall that the derivative of x is 1, and the derivative of a constant (such as 5) is 0. Thus...
d(x + 5) = 1 + 0 = 1
So, the derivative of x+5 is 1.
In fact, the derivative of x plus any constant is 1.
The sum rule can also be used for negative values, because in math, you can do subtraction through addition by simply adding a negative value. For example, "8 - 4" is the same as "8 + (-4)". In the first case, you're subtracting 4 from 8. In the second case, you're adding negative 4 to 8, which does exactly the same thing. Similarly, if you have a subtraction, you can calculate the derivative like this:
d(a-b) = d(a) + d(-b)
If we try subtracting something from x and calculating the derivative of the resulting function, the derivative will, again, always be 1. For example, if we have the expression "x - 5", well, using the sum rule, we'd say:
d(x - 5) = d(x) + d(-5)
The derivative of x is 1, and -5 is still a constant, so its derivative is 0.
d(x - 5) = 1 + 0 = 1
You can also just use the difference rule:
d(a-b) = da - db
If two differentiable functions a and b exist of the variable x, then the result of multiplying those functions (ab) is (the derivative of a) multiplied by b, plus (the derivative of b) multiplied by a. Or, as a mathematical equation:
d(ab) = (da)b + (db)a
Once again, just to make sure it's clear: The derivative of ab (which is a times b) equals ((the derivative of a) times b) added to ((the derivative of b) times a).
Notice that this is only true for multiplying two functions. If you are multiplying a constant by a function, then the rule is different:
The derivative of a constant times a function is the constant times the derivative of the function.
So, for example, the derivative of 5x is 5 times the derivative of x. The derivative of x is 1, so the derivative of 5x is 5 times 1, or 5.
a (da)b - (db)a d( - ) = ------------- b b^2
d(x^n) = nx^(n-1)
When you start to practice the power rule, you often end up with a long string of "x to some different power"-type formulas, so let's try one of those and see how it works.
Suppose you have this function:
3x^5 + 4x^4 + 6x^3 + 9x^2 + 19x + 2
That is 3 times (x to the power of 5), plus 4 times (x to the power of 4), etc. The derivative of this function is:
15x^4 + 16x^3 + 18x^2 + 18x + 19
Notice that for each term, we simply multiply the coefficient (the number before x) by the exponent, then subtract 1 from the exponent. Pretty straightforward, huh? For 9x^2, we get 18x (we omit the exponent of 1, because anything which doesn't have an exponent specified is assumed to be implicitly to the power of 1). For 19x, we get a derivative of 19, because anything to the power of 0 is 1, so x to the power of 0 would be 1, and 19 times 1 is 19. Finally, recall that the derivative of a constant is 0, so the 2 on the end has a derivative of 0; We can omit this entirely (since anything plus 0 is unchanged).
The power rule is also used to calculate the derivative of a radical. A radical can be expressed as a fractional power. For example, the square root of x is equivalent to x to the power of 1 over 2.
sqrt(x) = x^1/2
We'll use this if we want to find the derivative of the square root of x, then.
d(sqrt(x)) = d(x^1/2)
Keeping the power rule in mind, we can write:
1 -1/2
d(x^1/2) = - . x
2
In other words, we have x to the power of negative one-half, all multiplied by one-half.
Recall that anything raised to a negative exponent is actually one divided by the same thing with a positive exponent. So...
-1/2 1
x = ----
1/2
x
The bottom side of this fraction, x raised to the power of one-half, is the square root of x.
1 1 ---- = ------- 1/2 sqrt(x) x
Thus, the derivative of the square root of x is this multiplied by one-half.
1 1 1
d(x^1/2) = - . ------- = -----------
2 sqrt(x) 2 . sqrt(x)
The chain rule is a bit different from the other rules, because it doesn't represent a single specific arithmetic operation as a derivative, but rather, it represents a combination of two arithmetic operations. It's a little more complicated to use and understand than the other rules, but it should be reasonably easy if you can understand the other rules for derivatives.
As an example of where you'd use the chain rule, suppose that you wanted to find the derivative of the following:
(x+1)^2
In other words, you've got the square of (x+1), and you want to find the derivative for it. This is not a single operation; it's two operations, namely addition and exponentiation. You can't just use the sum rule or the power rule on this expression, because it's not just a sum or an exponentiation. To derive the derivative of this expression, you'll want to divide the expression into these two component parts. In other words, instead of turning it into a function which acts upon x, it will be two functions; one function will act upon x, and the other function will act upon the first function.
Suppose that we give the designation of a for the function which acts upon x. a, then, is x+1. If we call the other function b, then we can say that b acts upon a, and b = a^2.
Our expression, then, formatted for the chain rule, looks like this:
b(a(x))
If we continue the use the (somewhat mathematically unconventional) notation of indicating the derivative as a function d which acts upon something, then the derivative of our whole expression looks like this:
d(b(a(x)))
And here is where the chain rule comes in. The chain rule states this:
d(b(a(x))) = d(b(a)) * d(a(x))
To write this out textually: The derivative of a function b acting upon a function a, which in turn acts upon a variable x, is equal to the derivative of b acting upon a, multiplied by the derivative of a acting upon x.
To use our initial expression as an example, if we say that a=x+1, and b=a^2, then we want to first find the derivative of b acting upon a. Using the power rule, we can express this derivative like this:
b' = 2a ^ 2-1
(Remember, b' is the derivative of b, pronounced "b prime".) Of course, 2 - 1 is 1, and anything to the power of 1 remains unchanged, so 2a to the power of 2-1 is simply 2a, or 2 times a. So...
b' = 2a
Given that a = x + 1, we should also expand a:
b' = 2(x+1)
...Which multiplies algebraically to:
b' = 2x + 2
Now let's work on the other side of the multiplication operator in the chain rule. We need to find the derivative of a acting upon x, and since a = x + 1, we can use the sum rule to express this operation. The derivative of a sum is the sum of the derivatives, so...
a' = d(x) + d(1)
In other words, the derivative of a acting upon x is the derivative of x, plus the derivative of 1.
From here, it gets pretty simple. Remember, the derivative of a constant is zero, and 1 is a constant, so the last term in this expression is actually just adding zero. We can drop it, leaving us with:
a' = d(x)
It happens that the derivative of the variable x is 1. (This is another rule of derivatives.) So...
a' = 1
Having determined all this, we can combine them into our one big chain rule expression:
b' = 2x + 2
a' = 1
d(b(a(x))) = d(b(a)) * d(a(x))
d(b(a(x))) = 2x + 2 * 1
Of course, anything multiplied by 1 remains unchanged. So, our final answer is:
d((x+1)^2) = 2x + 2
The derivative of a sine is the cosine.
The derivative of a cosine is the negative sine value.
The derivative of a tangent is the secant squared.
The derivative of a cotangent is the negative, squared cosecant.
The derivative of a secant is the secant times the tangent.
The derivative of a cosecant is the negative cotangent times the cosecant.
The derivative of a logarithm is 1 divided by x.
After derivatives, the other main branch of calculus deals with integrals. An integral is actually a fairly intuitive concept that's not too difficult to understand, but working with integrals and using the formulas used to calculate them gets tough. That's where the real calculus starts coming into play.
Conceptually, an integral is really just a way of expression the area of a shape. Think about a function. Perhaps the graph of the function looks something like this:

The wavy line at the top represents a function. The straight vertical and horizontal lines are just the axes of the graph, and the line on the right where the function stops is some arbitrary point that we chose to cut off the graph. This forms an enclosed shape, as you can see. On the left, right, and bottom sides, it's bound by straight lines, but at the top, it's got that wavy function line. If you knew the dimensions of the straight lines and the function that gives the wavy line, how would you calculate the area of this shape? Well, the area of this shape is an integral, so if you can calculate it, you can calculate an integral.
Integrals are usually explained in terms of drawing rectangles over the shape. Suppose that you tried to approximate the area of the shape on the graph by drawing a row of rectangles over it, something like this:
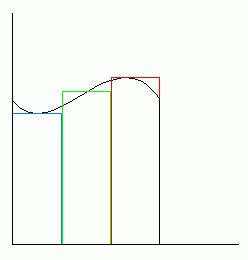
You remember how to calculate the area of a rectangle, right? It's easy: Just multiply the height by the width. If you wanted to get a number that's somewhere close to the area of the shape we want to find, you could just add up the areas of the rectangles. That wouldn't be exactly the right answer, because some of the rectangles contain space that's outside the bounds of the shape, and some of them exclude a bit of the area of the shape, but overall we might get a decent idea of the area of the graph.
It's easy to get a more accurate measure of the shape's area, though. Just draw more rectangles. If we add more rectangles to our graph, it might end up looking like this:
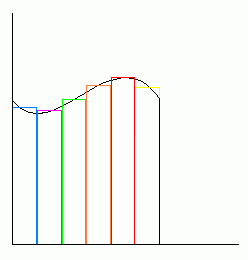
You can see that the more rectangles we add, the more accuracy we get in predicting the area of the shape. We could keep adding more and more rectangles, until eventually the rectangles become little more than thin lines. Ultimately, our measurements could become a series of points, taken at very close intervals on the graph.
Can you see where this is headed?
Recall that limits are used to calculate integrals.
The integral of a function is simply the limit of the area of all the rectangles added together as the number of rectangles approaches infinity. If we made infinitely many rectangles, their areas, added together, would equal the area of the shape under the function line in the graph.
A few specific symbols are used in the mathematical definition of an integral. The shape whose area we are trying to determine is bound on the left and on the right by arbitrary points which we define. These points are called simply a and b, with a being the x-value that defines the left edge of the shape, and b being the x-value that defines the right side of the shape.
A notation called Dx refers to the width of each of the rectangles. As the number of rectangles increases, the value of Dx gets smaller, since the rectangles become narrower. Dx is defined by the formula:
b - a ----- n
...Where b and a are the right and left sides of the shape respectively, and n is the number of rectangles we're using.
If you remember your sigma notation, it's now time to present you with the definition of the definite integral. It looks like this:
n *
lim n -> inf S f(xi).Dx
i=1
This may look a bit overwhelming at first, but stay calm, if you've read and understood everything up to this point, this definition of an integral is actually quite easy to understand once you pick it apart. First of all, notice that on the right side, we have Dx (which, as you'll recall, is the width of each rectangle) multiplied by f(xi), with an asterisk over the i in "xi". f(xi) represents the height of a rectangle taken at a certain x-value of i. As each rectangle is made on the shape, its height, which is received by returning the value which f gives for xi, is multiplied by Dx, which is the width of the rectangle, and this results in the area of that rectangle.
This operation of sampling rectangles and getting their area is repeated, and the individual rectangles' areas are added to each other. Since this sum operation continues into infinity (because the integral is rendered as the limit of this operation as n approaches infinity), the idea is that when infinitely many rectangles are positioned over the shape, their combined areas will equal the area of the shape.
It's obvious that this definition of an integral isn't something you can just sit down and calculate. While the concept behind it might be easy enough to understand, there's no way to simply use this as a formula by plugging in some values and seeing what answer comes out. The operation continues into infinity, and we can't perform an infinite number of addition cycles. So, like most other areas of calculus, the definition of this concept is a little unsatisfactory, because we can't actually use it. Instead, to actually start calculating integrals, you need to know a bunch of additional rules for working with them. This can become tiresome, because while there are only about a dozen rules you need to know for working with derivatives (the sum rule, the product rule, the chain rule and such), integrals have many more rules to learn.
As if that weren't bad enough, what has been described up to this point is actually just one type of integral: The definite integral. The "definite integral" is most intuitively described as the area bound by a function, but there is another type of integral that you must understand as well...
An antiderivative (which is also called the indefinite integral) is, quite simply, a derived function whose derivative is the original function.
That is, if you have a function called f, and you have another function called F (yes, capitalized instead of lowercase), and it happens to be the case that F'=f (that is, the derivative of F equals the original function f), then F is an antiderivative of f. The derivative of F is f.
If F is an antiderivative of f, then:
F'=f
Notice that we say an antiderivative of f, not the antiderivative of f. This is because, quite simply, a function can have many antiderivatives, not just one.
Be sure to carefully distinguish between definite and indefinite integrals. A definite integral is actually a number, a fixed value which represents the area of a shape bound by a function. An indefinite integral is not a number, but a function.
There are, of course, plenty of formulas used to calculate antiderivatives, but probably the most important one is this:
The antiderivative of x^n is:
x^(n+1) ------- n + 1
The simplest example of this is the antiderivative of x. Keeping in mind that a value with no exponent is actually to the exponent of 1, we see that the antiderivative of x is:
x^2 --- 2
Another fairly simple antiderivative rule: The antiderivative of a constant is that constant times x. So, for example, the antiderivative of 4 is 4x.
Continuing the rules for integration that we know so far, what would the integral be for the square root of x?
The square root of x is actually x to the power of 1/2. So...
� sqrt(x) = � x ^ 1/2
Using the general rule for the integral of x^n, we come up with...
x ^ 3/2
� x ^ 1/2 = � -------
3/2
Notice that what we have now is a division operation, in which the divisor itself is a fraction. If you'll recall your rules from working with fractions (see why remembering algebra is important?), dividing something by a fraction is the same as multiplying by the inverted fraction. That is to say, something divided by 3/2 is the same as that something multiplied by 2/3. So...
x ^ 3/2 2x^3/2 � -------- = ------- 3/2 3
Integrals also bear the same sum rule and difference rule as derivatives: The integral of a sum is the sum of the integrals:
�a+b = �a + �b
Similarly, the integral of a difference (subtraction) is the difference of the integrals:
�a-b = �a - �b
Let us now pause from the two main branches of calculus--derivatives and integrals--and examine something known as the fundamental theorem of calculus (sometimes abbreviated FTC), which helps make calculus clearer by bringing these two seemingly unrelated ideas together. At first glance, it might seem that derivatives and integrals have little to do with each other. In actuality, however, the discovery that they are actually quite closely related led to the foundation of modern calculus. Understanding the relationship between differentiation and integration helps make calculus make a lot more sense, by bringing together the individual threads of it and turning it into a more organized system, rather than the seemingly disjointed collection of rules and concepts that calculus often seems to be at first. If you can make a connection between differential calculus and integral calculus, then you will start to understand the real essence of calculus, and the key to this is the fundamental theorem of calculus. It's worth noting, in passing, that there's also a fundamental theorem of arithmetic, and a fundamental theorem of algebra, but those are often not studied by math students, because arithmetic and algebra can be understood and applied relatively intuitively, while calculus seems to be a largely useless study at first, before you can make sense of its fundamental theorem.
The simplest way of expressing the FTC is:
If F is an antiderivative of f, then the definite integral of f from a to b equals F(b) - F(a)
To put it another way: If F is any antiderivative (indefinite integral) function of f, then the area of the shape bound by the function curve of f, from x-value of a to x-value of b, is equal to F of b, minus F of a.
And there you have it. Derivatives and both types of integrals brought together in a single grand unifying theory. That's it. That's really all there is to it. And if you can understand everything that you've read thus far, then you should hopefully find it easier to bring together the different branches of calculus and understand how they work together.
The rules which are standard for derivatives (such as the product rule, the power rule, and the chain rule) have corresponding rules of integration. There are two particularly important rules for integration which are usually learned by calculus students who study integrals:
The product rule for derivatives corresponds to the integration by parts rule for integrals.
The chain rule for derivatives corresponds to the substitution rule for integrals.
Integration by parts is related to the product rule for derivatives. Recall the the product rule states this:
d(ab) = (da)b + (db)a
The derivative of (a times b) is equal to ((the derivative of a) times b) plus ((the derivative of b) times a).
Given that the integral we speak of is simply the antiderivative, it seems intuitive that...
� [(da)b + (db)a] = ab
...Right? All we're doing is reversing the product rule, so that instead of splitting the multiplication into an addition of two products, we're bringing them back together into the original product, before the derivative was calculated. If you know the product rule, this should seem like a reasonable theory.
Sure enough, this formula is an accepted calculus teaching, and it's called the integration by parts rule.
Now, this by itself probably doesn't seem too useful at first. "Okay, so if you have the derivative of one function times another function, added to the derivative of the second function times the first, and you want the antiderivative for that whole thing, then yes, this formula would seem useful. But how often do you have that exact arrangement?" Indeed, this formula as it's written here is not very practical. As you might imagine, however, there's a rearrangement coming. The equation given above can be changed, using a simple algebraic manipulation (again algebra becomes important!), to the following:
� (da)b = ab - � (db)a
All we did was subtract � (db)a from both sides. So now we have the formula for the antiderivative of (da)b, which is simply the derivative of one function, multiplied by another function. As you can probably imagine, this formula becomes quite useful sometimes.
Calculus textbooks usually like to express this formula in terms of u and v rather than a and b, so your calculus textbook will probably have this same formula, written something like this:
� u(dv) = uv - � v(du)
But wait, there's more. Remember, integration by parts corresponds to the product rule. Using integration by parts, we can find the integral of *any* product. How can we do this using the formula we see here? Suppose that, instead of a function times a derivative, we simply had two functions multiplied. How would we use this formula for them? By converting one function into its antiderivative!
What we're saying here is, suppose you simply wanted to find the indefinite integral for two functions called u and v multiplied together. So, our expression looks like this:
� uv
What we need to do is convert this "two independent functions multiplied together" format into "function multiplied by the derivative of another function" format. All you need to do this is convert v into its antiderivative, and then change "v" to "derivative of v":
uv = u * d( �v )
u times v is the same as u times the derivative of the antiderivative of v. After all, derivation and antiderivation are opposite functions, so if you do one and then do the other, you're back where you started.
Let's try to make an example of this rule using some very simple values. Let's say we want to find the indefinite integral of 3 times 5.
� 3 * 5 = ?
Of course, a real mathematician would simply multiply the 3 times 5 first, come up with 15, and then use the rule for the antiderivative of a constant to determine that the answer is 15x. So we already know the answer, but let's try going through the steps of the integration by parts rule to see if we come out with the same answer, as a sort of double-check. We should.
First, we need to convert this into "function multiplied by the derivative of another function" format. So, let's turn 5 into its antiderivative, and then 3 can be "u" in the formula, and the antiderivative of 5 can be "v". The antiderivative of 5 is 5x, so...
� 3 * d( 5x ) = ?
Now we can write out the rest of the formula given above for integration by parts:
� 3 * d( 5x ) = 3*5x - � [5x*d(3)]
Okay, 3 times 5x is 15x, we know that much.
� 3 * d( 5x ) = 15x - � [5x*d(3)]
Also, the derivative of a constant is zero, so the derivative of 3 is zero.
� 3 * d( 5x ) = 15x - � [5x*0]
Of course, anything times 0 is 0, so 5x times 0 is 0.
� 3 * d( 5x ) = 15x - � 0
The indefinite integral of zero is zero.
� 3 * d( 5x ) = 15x - 0
And finally, subtracting zero doesn't do anything, so we can omit the -0 at the end.
� 3 * d( 5x ) = 15x
It worked! Our answer is, indeed, 15x. The indefinite integral of the multiplication operation in which 3 is multiplied by 5 is 15x.
More advanced calculus classes usually require you to study about calculus of several variables, which is similar to regular calculus, except that whereas beginning calculus expects you to calculate (for example) a derivative with respect to x (which is only one variable), in later calculus you'll have to calculate a derivative with respect to more than one variable.
The fundamental model of a function is a two-dimensional graph, in which the horizontal axis (x) is the domain, and the vertical axis (y) is the range. For every value of x, there is a corresponding value of y. x is the "input" variable for the function, and y is the "output" value for the function. But now imagine that you laid down a two-dimensional graph on a tabletop so that it's flat. Above this graph is three-dimensional space; in addition to being able to move along the x axis and the y axis (both of which would move you sideways), you can also move up. This new vertical axis can be called the z axis, and the space that you're imagining now is simply a three-dimensional space.
Typically, a function with two input variables has the two input variables named "x" and "y", and the output variable is "z".
Recall that for a function to be a real mathematical function, there can only be one possible output for a specific set of inputs. In the function with only one input variable called x, x can be any number, but whatever x is, there can only be one corresponding possibility for y. If x is 3, for example, it shouldn't be possible for y to be either 7 or 12; if y can be more than one thing for the same value of x, then this isn't a function we're talking about. However, the inverse is not true; y can be the same thing many times. For example, if y is 5 when x is 3, and y is also 5 when x is 9, then that's just fine; the output variable can repeat previous values, but it can only have one possibility for each value of the input variable.
The same is true for a function with two input variables. If you set x to be 3, and y to be 9, then there should be one and only one possible output for z. If it's possible for z to be either 2 or 4, then this isn't a real function. But if z has just one possible value for each combination of x and y, then you can start to graph out a three-dimensional function. For each value of x and y (which forms an intersection at the bottom of our three-dimensional space), there is a corresponding value for z. With these three coordinates, we can mark a point in the 3D space. If we do this for every combination of x and y, the resulting function forms a sheet that rises up when z increases and slopes down when z decreases. Whereas the graph of a function with one input variable is a line that can move up and down, the graph of a function with two input variables is like a sheet of paper or fabric.
In actuality, functions can have an unlimited number of variables. You can have a function with 10 input variables if you want. The "one output value for each combination of input values" rule still applies. The only issue with functions of more than two input variables is that they can't be graphed as intuitively in a visual sense. Undergraduate calculus courses usually don't talk about functions with more than two input variables too much.
A basic derivative in calculus represents the slope of a line. At any point in its existence, a line on a 2D graph has a given slope. Seems simple enough, right?
What if you wanted to calculuate the slope of the graph formed by a 3D function? Doesn't seem so easy now, does it? The problem is that each point in the 3D graph actually has more than one slope. Imagine a ramp, like the kind you use to roll things to or from a higher place to a lower place. If you consider the slope of the ramp in the direction in which you walk along the ramp, it has some slope, right? But what if you consider the slope of the ramp perpendicular to the direction in which you walk along the ramp? The ramp has no slope in that direction; it's flat. The slope along that line is zero. Similarly, a three-dimensional graph has different slopes at each location, depending on which axis you want to consider the slope of.
A three-dimensional graph doesn't simply have some given slope for any point on it. Instead, we need to consider the slope of only one of its horizontal axes. In fact, not only that, we actually need to consider just the slope for one value of a horizontal axis. For example, in a 3D graph, consider all the graph values in which x equals 3. All of these graph points line in a single flat plane. Indeed, they form a two-dimensional line graph in that plane. Using that line graph, you can calculate the derivative for all values of z in which x equals 3. Since this is only a derivative for a limited subset of the possible values of z, this derivative is a partial derivative. We must work with partial derivatives when we use 3D functions, because there is no one derivative for the entire function.
A related concept is the tangent plane. If you pick a point on the 3D graph, you can calculate the tangent line for that point along both axis x and axis y. There are then two tangent lines which intersect at that point. A tangent plane is simply a flat 2D plane which is in line with these two tangent lines. If you lay a spherical ball on the floor, then the floor forms a tangent plane to the point on the surface of the ball which the floor is touching.
A differential equation is basically just an equation which contains a derivative. Introductory differential calculus is mostly just about trying to figure out what *is* the derivative of some expression, but once you get beyond that, you start to use the derivatives within formulas, just like any other variable.
As an example of a very simple (by mathematicians' standards) differential equation, consider something like this:
f'(x) = 2
Okay, so we see that we have a function whose derivative is 2. That means that at every point along the function, the slope of the function's line is 2. To "solve" a differential equation like this usually means to find a function which we can use for f which satisfies this equation. (Or, solving a differential equation can mean to find *ALL* the functions which satisfy the equation.)
A simple solution for this equation is f = 2x. Pretty straightforward. But for most differential equations, finding a solution is not so easy. Part of the problem is that most differential equations have many solutions, and unlike the practice of calculating derivatives or integrals, in which you're guided by a given set of rules (even if those rules are convoluted and difficult at times), differential equations don't always have a categorized rule that you can use to solve them. Differential equations are almost as much an art as they are a science, and people who work with them develop techniques and tools that usually help them get closer to a solution, but aren't guaranteed to accurately solve the equation. It all makes differential equations one of those post-calculus fields of study that causes engineering students to worry, and liberal arts students to be glad they didn't go into engineering.
Fourier (pronounced "four-yay") analysis is basically the practice of representing a function by a combination of several other functions.
In physics, "interference" is an important and interesting subject that arises when two waves meet each other. Fundamentally, there are two types of interference: Constructive interference and destructive interference. Constructive interference is when both waves have the same polarity, i.e. they are moving in the same direction. Where this happens, the strengths of the waves combine. Destructive interference is when the waves have opposite polarity; in such a case, the two waves will diminsh each other.
The result of all this is that if you combine two waves together (be they sound waves, electrical waves, or some other kind of wave), they will combine to produce a waveform that probably doesn't look much like either of the original waves.
This concept is taken much further in Fourier analysis, where you can take any wave that can be represented by a mathematical function and describe that function (and subsequently the wave) as a combination of several other waves.
A simple example might help clarify this. Suppose that you play a 1,000 hertz sine wave and a 1,500 hertz sine wave together. In the air, these frequencies will combine, and if you use a microphone and an oscilloscope to "see" what the resulting sound looks like, you won't see either of the original wave shapes; instead, you will see some other function. However, using Fourier analysis, you could take that summed function and analyze it down to its component frequencies, determining that the wave consists of 1,000 hertz and 1,500 hertz mixed together. A concept like this has an important real-world application in deciphering touch-tone telephone sounds. When you push a button on a touch-tone telephone, the resulting tone is not actually one note, but two notes played together. For example, the "1" button on a phone plays 697 hertz and 1,209 hertz together. When the telephone company's switch wants to determine what button you pushed, it does a Fourier analysis on the sound it "hears" to determine the two frequencies the sound is made of.
There are two main types of Fourier analysis: The Fourier series, and the Fourier transform. Of these, the Fourier series is usually considered the first of the two subjects to learn, since the Fourier transform expands on concepts used in the Fourier series. Therefore, we will study the Fourier series first.
The Fourier series expresses a function as a sum of component frequencies. By contrast, the Fourier transform is not a sum so much as it is a function that represents the frequency domain of the original function. The Fourier series requires that the function you are working with be periodic; that is, the function must eternally repeat a certain wave shape. In contrast, the Fourier transform can be used with an aperiodic (non-periodic) function; even random noise can be Fourier transformed, but it cannot be represented as a Fourier series unless it's periodic.
First of all, let's understand the basic format of the generalized sine function.
The simplest form of the sine function is simply sin(x), or y = sin(x). This function produces a nice sine wave with a maximum value of 1 and a minimum value of -1. (That is, the top peaks of each wave will be at y = 1, and the bottom troughs will be at y = -1.)
We can change the amplitude of this wave by simply adding a multiplier before the sine function. For example, if we multiply the sine function by 2, so that our function becomes y = 2 * sin(x), then the sine wave will peak at 2. The amplitude is commonly represented by the letter a.
Similarly, we can change the frequency of this sine wave by multiplying or dividing its operand. For example, if you multiply the operand by 2 so that the formula becomes y = sin(x*2), you will double the frequency of the sine wave.
A number that you will often see when doing Fourier analysis is 2 times pi. One of the significances of this number is that if you multiply the basic sine wave by it, then the period (width) of one cycle of the wave becomes exactly 1 (assuming the sine wave is being calculated by radians, not degrees). In other words, if you graph a function of y = sin(2*pi*x), then the result is a sine wave with a period of exactly 1.
Often when using sine functions, the term radian frequency is used. This is a value equal to 2*pi*f, where f is the actual frequency of the sine function. For example, suppose you wanted to make a sine wave with a period of 2; the frequency, then, would be 0.5, so to make this sine wave, you'd use the formula y = sin(2*pi*0.5*x). The lowercase Greek letter omega is usually used to represent the radian frequency; this character looks like this: ω (If your browser doesn't display the character correctly, basically it looks sort of like a rounded-out lowercase w.) Don't confuse this with the uppercase Greek letter omega (Ω), which doesn't get used much in math but is used ubiquitously in electrical engineering as a symbol for ohms (the unit of electrical resistance).
We've now outlined two key portions of the basic sinusoidal function. We have mechanisms to mathematically control the function's amplitude (how high the wave is) and frequency (how many times the wave occurs per horizontal unit). There are just two other things that we need to be able to control: The wave's horizontal deflection, and its vertical deflection.
The horizontal deflection of the wave, often called the wave's phase, can be controlled by a simple addition or subtraction operation to x. For example, the function y = sin(x+1) will shift the wave horizontally. Similarly, the wave's vertical deflection or vertical offset can be changed by a simple addition or subtraction after the entire operation is over. For example, y = sin(x) + 1 gives you a sine wave that's raised so its lower peaks are actually on the x-axis.
So, in conclusion, the complete format for a sinusoidal function is:
y = a * sin(ω * (x + p)) + v
...where a is the amplitude of the wave, ω is the radian frequency of the wave (2 * pi * frequency), p is the phase shift of the wave, and v is the vertical deflection of the wave.
A harmonic is a sinusoid function with its frequency multiplied by some whole number.
For example, consider the simple sine wave function, y = sin(x). You can double the frequency of this function by multiplying x by 2, so that the formula becomes y = sin(2*x). This function is exactly the same as the original, except with its frequency doubled. Therefore, this function is the second harmonic of the original function.
Similarly, y = sin(3*x) is the third harmonic of the function. And so on. Because whole numbers go on forever (there is no "last number"), harmonics go on forever as well. Every periodic function has infinitely many harmonics.
When speaking of harmonics, the frequency of the original function which the harmonics are harmonics of is called the fundamental frequency.
Complex numbers are usually reviewed in pre-calculus classes. If you're at the point where you're working with Fourier transforms, you should probably have learned about complex numbers already, but you may well have forgotten them, since they're often not that useful. So let's review complex numbers, their two notations (rectangular and polar), and how they can be expressed geometrically.
First of all, you need to understand what the imaginary unit is. The imaginary unit is the square root of -1. It is computationally impossible to have a square root for any negative number (since any non-zero value is positive when squared), which is why this number is called "imaginary". You can't write its numerical value because it doesn't have one, so it is instead referred to simply as i. (Electrical engineers often prefer to use j instead of i, because in electrical engineering, "I" is used as the symbol for electric current, while "J" is not usually used for anything else. Pure mathematicians more commonly use i.)
An imaginary number is a normal real number multiplied by i. For example, 4i is an imaginary number.
A complex number, in essence, is an entity containing two parts. One part of the complex number is a normal real number; this is the real part of the complex number. The other part of the complex number is an imaginary number, constituting the imaginary part of the complex number.
Because a complex number contains two values, it is not usually graphed in one dimension like regular numbers. If you think of the "number lines" that you often see in elementary math texts, they really are just a straight line, because regular numbers proceed in order: 1, 2, 3, 4, 5, and so on. A complex number, however, is graphed in two dimensions. It is common practice when graphing complex numbers to use the horizontal axis for the real part of the complex number, and the vertical axis for the imaginary part of the complex number. (You CAN make a graph using only one part of a complex number, but then you must explicitly specify which part you are using: Either the real part or the imaginary part.)
The rectangular notation for a complex number looks like this:
x + iy
Clearly, using this notation, the real part of the complex number is simply x, while the imaginary part is iy. This can be represented on a graph by a point with horizontal coordinate x and vertical coordinate y.
Polar notation isn't quite as straightforward, because it expresses points using a length and an angle, rather than simply a horizontal length and a vertical length. The polar notation for a complex number looks like this:
r cos(θ) + ir sin(θ)
...Where r is the length of the line extending from coordinate 0,0 to the point in question, and θ is the angle of the line from the x-axis. (θ is the lowercase Greek letter theta, often used to represent angles in trigonometry and complex numbers.)
Using polar notation, it becomes clear that r cos(θ) is the real part of the complex number, and ir sin(θ) is the imaginary part.
Fourier analysis expresses functions as e raised to some exponent which includes i (which is the square root of -1). Before you can really understand Fourier analysis, you need to understand Euler's formula, which explains how to understand something like eix. Although this usage of e does refer to the base of the natural logarithm (in other words, e is a constant equal to 2.71828182845904523536...), you don't really need to worry about this fact, since Euler's formula alters this form in a way that doesn't use e at all.
Euler's formula says this:
eix = cos(x) + i sin(x)
(This formula assumes that the sin and cos functions are using radians, NOT DEGREES.)
Additionally, sometimes the i is made negative, in which case you'd use this complement to the above formula:
e-ix = cos(x) - i sin(x)
Now, if you remember polar notation for complex numbers, you should realize that this gives you an easy way to write polar notation without having to write out the "sin" and "cos" functions. Using this notation, the "x" becomes θ (the angle for the sin and cos functions). This leaves one question open: Where's the length for the polar notation?
Well, you'll have to add it in. It happens, conveniently, that:
reix = r cos(x) + ir sin(x)
So when you see something like reix, you're actually seeing shorthand for a polar coordinate, where r is the distance of the point from 0,0 and x is the angle.
In Fourier analysis, we speak of signals. A signal in this context is really just a function. The vertical axis of the signal is its range, and the horizontal axis represents time. (For this reason, the letter "t", for time, is often used to refer to the horizontal axis, instead of the "x" more common when working with functions in basic algebra.)
A complex exponential formula has this basic form in Fourier analysis:
reiωt
...Where ω is, as discussed before under "Sinusoidal functions", the radian frequency of the signal, and t is time, used instead of x to refer to the graph's horizontal axis.
It is the standard, when using such notation in Fourier analysis, to use only the real part of the resulting complex number in a graph.
Applying Euler's formula, you should be able to discern that the real part of the above formula is r cos(ωt).
Therefore, when graphing reiωt, the horizontal axis is t, and the vertical axis is the output of the function r cos(ωt).
The basic premise of the Fourier series is this:
Any periodic function can be expressed as the sum of a sinusoid function plus all that sinusoid function's harmonics.
The trick here is that you get to set the harmonics' amplitudes to whatever you want. Using an infinite series of a sinusoiud and all its harmonics, and setting each harmonic's amplitude to some particular value, you can generate any periodic function.
For example, consider a very simple function: A sine wave. Let's call this sine wave George. To keep things simple, imagine that George has a period of 1 (and therefore also a frequency of 1). To represent this function using the Fourier series, you'd start off with a basic sinusoid function with a frequency of 1. You would set this base function's amplitude to whatever amplitude George has. You might notice that doing this perfectly re-creates George, so what are you going to do with the infinite series of harmonics for this sinusoid function? Simple: Set their amplitudes to zero.
That paragraph may take a bit of re-reading for it to make some sense, but that's really how you represent a plain sine wave using a Fourier series: A sinusoid at some fundamental frequency, then an infinite series of its harmonics with zero amplitude. Since these harmonics have zero amplitude, adding them in does nothing, so you end up with a perfectly re-created sine wave.
Now let's consider another classic Fourier series representation: A square wave.
To represent a square wave using a Fourier series, start off with a sine wave that has the same period as the square wave, but a slightly higher amplitude. After that, all this base sine wave's even harmonics will have a zero amplitude. (That is, the second harmonic, the fourth harmonic, the sixth harmonic, and so on will all be zero, and therefore have no effect on the final summed function.) The odd harmonics will all be used, however. The third harmonic will have an amplitude that is 1/3 of the fundamental frequency's amplitude. The fifth harmonic will have an amplitude of 3/5 of the third harmonic's amplitude. The seventh harmonic will have an emplitude of 5/7 of the fifth harmonic's amplitude. And so on, ad infinitum. This series of harmonics, added together, will yield a square wave.
You can see, then, that the trick to getting a Fourier series right is to figure out the amplitudes of each harmonic. You get started making a Fourier series by simply selecting a sinusoid wave with the same frequency as the signal you're analyzing; that's usually fairly simple, although sometimes it can be a trick just to figure out what the fundamental frequency of a signal is. Once you've got the fundamental frequency figured out, all that's left to do is determine what each harmonic's amplitude will be. The amplitude for each harmonic is called a Fourier coefficient. Calculating the values of the Fourier coefficients is one of the key tasks of Fourier analysis.
Before we learn about Fourier transforms, you should understand the Dirac delta function, because it gets used a lot to express Fourier transforms. Luckily, the Dirac delta function is pretty easy to understand.
The Dirac delta function is simply a spike. The classical Dirac delta function is a vertical line extending upward forever from the horizontal point 0 (i.e. where x=0 on a graph). The line has an infinite height.
The Dirac delta function is often represented by the lowercase Greek letter delta, which looks like this: δ
Although the classic form of this function occurs at x=0 and has an infinite height, sometimes this function is simply used to represent any impulse. In these cases, the Dirac delta function typically uses notation similar to this:
a δ(x)
...Where a is the height of the line, and x is the line's horizontal location. For example, the function 5 δ(3) is a vertical line which is 5 units high, located at x=3.
The Dirac delta function is actually not a true function, but it often gets treated like one. It's an easy way to specify an impulse of whatever size and location you want.
The Fourier transform takes a function and represents it as the function's frequency spectrum.
The Fourier transform can be something difficult to understand, so before we get into the details of how it works, let's try a few examples of some fundamental Fourier transforms to see if we can understand them intuitively.
Let's start with the Fourier transform of the cosine function y = cos(x). (I'll explain later why I'm starting specifically with the cosine and not the sine function.) The Fourier transform of the cosine function is two vertical spikes; you guessed it, these are Dirac delta functions. Both spikes have a height equal to half of the cosine wave's amplitude. One is located where x=f (f being the frequency of the cosine), while the other is located where x=-f.
The most confusing aspect about this result (and the first thing people usually ask at this point) is: Why is there a negative frequency? What is a negative frequency, anyway? To try and understand this concept, imagine a phasor, which is a vector that rotates around on its tail. As the phasor spins around, it traces the vertical component of a sine or cosine wave. If you imagine a pen moving across a piece of paper which, horizontally, keeps moving to the right at a constant speed, but vertically follows the motion of this phasor, the pen will trace out a sinusoidal wave, which could be either a sine or a cosine wave (or neither) depending on where it starts.
In any case, because the pure cosine function starts at a maxima (that is, there is a vertical peak where x=0), the phasor can rotate in either direction if you start tracing from 0, and the resulting wave will look exactly the same. The pure cosine function is horizontally symmetrical, whether you go forward or backward.
In contrast, the pure sine wave function is not symmetrical in this way. The sine wave's Fourier transform is even more confusing, and this is why I arrive at it now after starting with the cosine function. The Fourier transform of the pure sine wave function is, again, two Delta dirac functions with amplitudes half that of the original wave, but this time, the delta function at x=-f goes up, while the one at x=f goes down. (In contrast, in the cosine function's Fourier transform, both of the delta functions go up.) What does this mean?
The pure sine wave function is not symmetrical. At x=0, the function's output increases as you move to the right, and decreases as you move to the left. In fact, the pure sine wave function is an odd function, which is a function in which f(x) = -f(-x). For example, whatever the function output is at x=3, the output will be the inverse of that at x=-3. Since the sine function is an odd function, its Fourier transform is an odd function too. If you imagine a phasor tracing out the sine function beginning from x=0, the phasor traces out one wave as it moves clockwise, and exactly the opposite wave as it moves counterclockwise.
A much easier Fourier transform to understand is that of a horizontal line. Any function is which y is a constant (for example, y=5) is a horizontal line. A function like this is sometimes called "DC" in signal analysis, because it is identical to the plot of a DC electrical input. Anyway, what do you think are the frequencies present in this signal? It seems pretty intuitive that there aren't any; the frequency is zero, right? It turns out that this is exactly correct. The Fourier transform of a DC function is a Dirac delta spike at x=0, with an amplitude equal to the vertical value of the horizontal line. Simple, right?
A considerably less intuitive Fourier transform is that of this Dirac delta function. Most Fourier transforms, interestingly enough, are reversible by simply Fourier transforming them again. Indeed, such is the case with the function we've just looked at: If we Fourier transform a Dirac delta spike at x=0, the result is a DC function. How can this be? A spike has no "frequency"; it's a single impulse existing in space, not a repeating function. Recall, however, that the Fourier transform can be applied to non-repeating ("aperiodic") signals as well as repeating ("periodic") ones. Basically, if you merged together a whole bunch of sinusoidal waves which encompassed *ALL* the frequencies and had the same amplitude, they would cancel out to create nothing except a single spike at x=0. Thus, that spike actually has all the frequencies from negative infinity to infinity, and they're all present with the same amplitude. Thus, the frequency spectrum is a horizontal line; a DC function.
(More to come, hopefully.)